Introduction
Imagine you’re building the next Netflix. Millions of users across the globe are streaming content, updating their profiles, and adding shows to their watchlists simultaneously. How do you ensure that when a user in Tokyo adds a show to their list, a user in New York sees it immediately? What happens when network issues strike? Welcome to the world of distributed systems, where the CAP theorem reigns supreme.
What is the CAP Theorem?
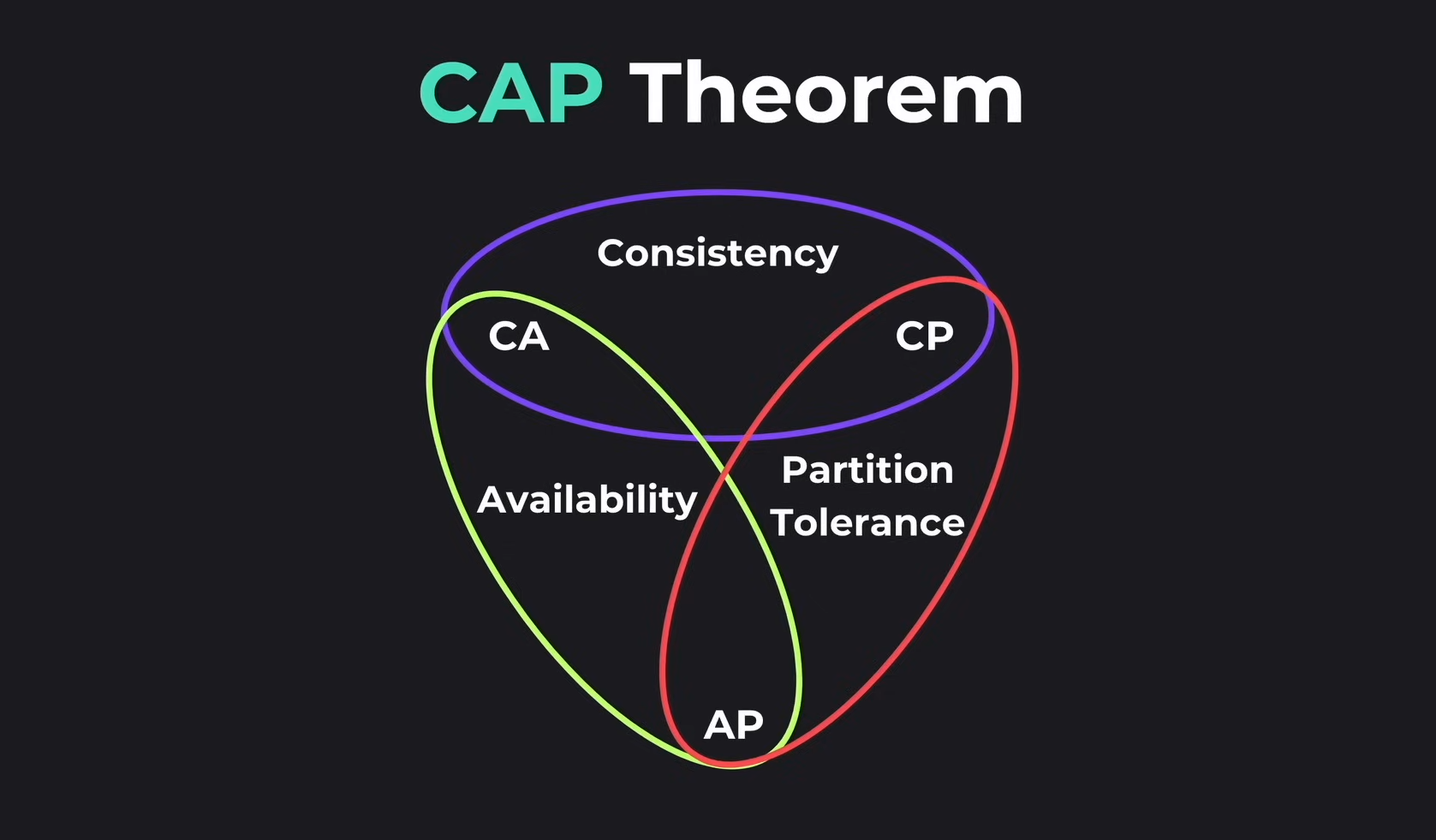
The CAP theorem, proposed by computer scientist Eric Brewer in 2000, is one of the most fundamental principles in distributed systems. It states that in any distributed data store, you can only guarantee two out of three properties at the same time:
C - Consistency: Every read receives the most recent write or an error. All nodes see the same data at the same time.
A - Availability: Every request receives a response (without guarantee that it contains the most recent write). The system remains operational even when nodes fail.
P - Partition Tolerance: The system continues to operate despite network partitions (communication breakdowns between nodes).
Here’s the crucial insight: network partitions are inevitable in distributed systems. Cables break, switches fail, and data centers lose connectivity. Since partition tolerance is non-negotiable in real-world systems, you’re actually choosing between consistency and availability when partitions occur.
Understanding Each Property in Depth
Consistency (C): Everyone Sees the Same Truth
Consistency means that all nodes in your distributed system see the same data at the same time. If you write a value to the system, any subsequent read from any node will return that value (or a newer one).
Think of consistency like a synchronized classroom where every student has the exact same textbook page open. When the teacher says “turn to page 42,” every single student must be on page 42 before class continues.
Real-world analogy: Imagine a bank account with $1000. You withdraw $200 from an ATM in New York. Consistency guarantees that if someone checks your balance from an ATM in Los Angeles immediately after, they’ll see $800, not $1000. There’s no confusion about the current state.
Technical deep dive: In a consistent system, writes are typically propagated to all replicas before acknowledging success. This often involves distributed consensus algorithms like Paxos or Raft, or techniques like two-phase commit (2PC).
Availability (A): Always Ready to Respond
Availability means the system always responds to requests, even if some nodes are down. Every request gets a response, though it might not contain the most recent data.
Think of availability like a 24/7 convenience store with multiple locations. Even if one store is closed for renovations, you can always find another store that’s open and can serve you.
Real-world analogy: Imagine a social media feed. When you refresh, you always see something, even if the system is under heavy load or some servers are down. You might not see the absolute latest posts, but you’re never faced with a blank screen saying “Service Unavailable.”
Technical deep dive: Highly available systems often use techniques like replication, load balancing, and graceful degradation. They prioritize responding to requests over ensuring all nodes agree on the data.
Partition Tolerance (P): Surviving Network Splits
Partition tolerance means the system continues to function even when network failures prevent some nodes from communicating with others. The system can survive a “split brain” scenario.
Think of partition tolerance like a company with offices in different cities. Even if the internet connection between New York and London offices goes down, both offices can continue working independently.
Real-world analogy: During a natural disaster, cell towers might lose connectivity to the main network. Partition-tolerant systems ensure that local operations can still function, even if they can’t immediately sync with the central system.
Technical deep dive: Partitions are inevitable in distributed systems due to network failures, hardware issues, or even software bugs. A partition-tolerant system has strategies to detect partitions and handle them gracefully.
The Three Combinations: Picking Your Trade-off
Since partition tolerance is mandatory in distributed systems (networks will fail), you’re really choosing between CP (Consistency + Partition Tolerance) and AP (Availability + Partition Tolerance) systems.
CP Systems: Consistency + Partition Tolerance
Trade-off: When a partition occurs, CP systems sacrifice availability to maintain consistency. Some nodes may refuse to respond until they can guarantee they have the latest data.
When to use: Financial transactions, inventory management, configuration systems, any scenario where showing incorrect data could cause serious problems.
Real-world examples:
-
Banking Systems (Wire Transfers)
- When you initiate a wire transfer, the system needs to ensure the money is debited from your account exactly once and credited to the recipient exactly once
- If network partitions occur, the system may temporarily block transactions rather than risk double-spending
- Better to show “Service temporarily unavailable” than to lose money
-
MongoDB (with default settings)
- MongoDB prioritizes consistency by default
- During network partitions, secondary replicas that can’t reach the primary will refuse read operations (unless you explicitly configure them otherwise)
- This ensures you never read stale data
-
Google Cloud Spanner
- Uses atomic clocks and GPS to maintain global consistency
- During partitions, may reject writes to maintain consistency guarantees
- Ideal for financial services needing global consistency
-
Airline Booking Systems
- When you book a seat, the system must ensure that exact seat isn’t double-booked
- If the network is partitioned, the system might prevent bookings rather than risk selling the same seat twice
- Consistency prevents the nightmare of two passengers assigned to the same seat
-
Distributed Configuration Systems (etcd, Consul)
- Used for storing critical configuration data and service discovery
- Must ensure all nodes agree on configurations (like which server is the leader)
- Temporarily blocking reads/writes is acceptable; distributing wrong configuration could crash entire systems
Example scenario: Imagine an e-commerce checkout system during a network partition. A CP system might display “Checkout temporarily unavailable” rather than risk charging a customer twice or not charging them at all.
AP Systems: Availability + Partition Tolerance
Trade-off: When a partition occurs, AP systems sacrifice consistency to maintain availability. All nodes remain responsive, but might return stale or conflicting data.
When to use: Social media, content delivery, caching systems, any scenario where temporary inconsistency is acceptable and availability is critical.
Real-world examples:
-
Amazon DynamoDB (eventual consistency mode)
- Designed for high availability across global regions
- During partitions, all nodes continue serving requests
- You might briefly see stale data, but the system is always responsive
- Perfect for shopping carts, session management, product catalogs
-
Cassandra
- Highly available distributed database used by Netflix, Apple, and Instagram
- Tunable consistency levels allow trading consistency for availability
- During network issues, nodes continue accepting writes and resolving conflicts later
- Netflix uses it for viewing history—if you watch an episode, slight delays in syncing across devices are acceptable
-
DNS (Domain Name System)
- Must be available 24/7—internet depends on it
- Uses eventual consistency with TTL (Time To Live) caching
- When you update DNS records, changes propagate gradually
- Temporary inconsistency (some users seeing old IP) is acceptable; DNS downtime is not
-
CouchDB
- Designed for mobile and offline-first applications
- Allows each node to accept writes independently
- Conflicts are resolved later using versioning and conflict resolution strategies
- Perfect for apps that need to work offline (like note-taking apps)
-
Social Media Feeds (Facebook, Twitter, Instagram)
- Must always be available—users expect instant access
- If you post something, followers might not see it for a few seconds
- Temporary inconsistency (your friend doesn’t see your post immediately) is fine
- Total unavailability would drive users away
-
Shopping Carts (Amazon, eBay)
- Amazon famously chose availability for shopping carts
- If you add an item to your cart, it’s always accepted
- If network issues cause conflicts (same item added twice), the system merges carts
- Better to have duplicate items in cart than lose cart entirely and frustrate customers
Example scenario: When you like a post on Instagram during network issues, the like is immediately shown to you (availability), but might take a few seconds to appear to other users (eventual consistency).
CA Systems: Consistency + Availability (The Myth)
The reality: CA systems can only exist in non-distributed systems (single-node databases) or when you assume network partitions will never happen (which is unrealistic).
Why they’re impractical: In any system distributed across multiple nodes or locations, network failures are inevitable. Physics and hardware guarantee this.
Traditional example: A single MySQL database on one server is “CA”—it’s consistent and available, but only because there’s no distribution. Once you replicate it across multiple servers, you must handle partitions.
Deep Dive: Real-World System Design Decisions
Case Study 1: Netflix’s Viewing History
The problem: Millions of users watching content globally. When you pause a show on your TV, you want to resume from the same spot on your phone.
The choice: Netflix chose AP (Availability + Partition Tolerance)
Why:
- Users must always be able to watch content (availability is paramount)
- A few seconds delay in syncing watch position across devices is acceptable
- Network partitions between regions shouldn’t prevent video streaming
How they did it:
- Uses Cassandra for storing viewing positions and user preferences
- Each region can operate independently during partitions
- Conflicts (watching same show on two devices) are resolved using timestamps
- Eventual consistency ensures data propagates when network recovers
Trade-off accepted: You might restart an episode on your phone that you already finished on your TV if the sync hasn’t completed yet. This minor inconvenience beats not being able to watch at all.
Case Study 2: Stripe’s Payment Processing
The problem: Processing billions of dollars in payments. Every transaction must be accurate—no double charges, no lost payments.
The choice: Stripe chose CP (Consistency + Partition Tolerance)
Why:
- Financial accuracy is non-negotiable
- Better to fail a transaction than to charge incorrectly
- Users accept occasional “try again” messages if it guarantees correctness
How they did it:
- Uses distributed databases with strong consistency guarantees
- Implements idempotency keys to prevent duplicate charges
- Employs distributed transactions and two-phase commit for multi-step operations
- During partitions, may temporarily reject transactions
Trade-off accepted: During rare network issues, some payment attempts might fail and need to be retried. This is far better than the alternative of charging customers multiple times.
Case Study 3: WhatsApp Message Delivery
The problem: Billions of messages sent daily. Users expect instant messaging even with poor connectivity.
The choice: Hybrid approach, leaning toward AP
Why:
- Messages must be deliverable even in poor network conditions
- Eventual consistency is acceptable for message delivery
- Users understand there might be delivery delays
How they did it:
- Messages stored locally first (availability)
- Background sync when network available (eventual consistency)
- Uses acknowledgment system (checkmarks) to indicate delivery status
- Server-side storage uses eventual consistency
Trade-off accepted: Messages might arrive out of order during network issues, or delivery might be delayed. But users can always send messages (they just might be queued).
Case Study 4: Google Docs Collaborative Editing
The problem: Multiple users editing the same document simultaneously from around the world.
The choice: AP with clever conflict resolution (Operational Transformation)
Why:
- Users must always be able to type and edit (availability critical)
- Network partitions shouldn’t stop collaboration
- Conflicts can be resolved programmatically
How they did it:
- Uses Operational Transformation (OT) to merge concurrent edits
- Each user’s edits are immediately visible locally
- Changes propagate and merge asynchronously
- Special algorithms ensure all users eventually see the same final document
Trade-off accepted: During network partitions, users might temporarily see different document versions. When connectivity returns, edits are merged intelligently.
Case Study 5: Stock Trading Systems
The problem: Executing trades on stock exchanges where milliseconds and accuracy matter.
The choice: CP (Consistency + Partition Tolerance)
Why:
- Regulatory requirements demand accuracy
- Double-executing a trade could cost millions
- Price consistency across the system is mandatory
How they did it:
- Uses distributed consensus for order matching
- Implements strict two-phase commit for trade execution
- Employs atomic broadcast for price updates
- During partitions, trading may halt rather than risk inconsistency
Trade-off accepted: Trading might pause during extreme network events. This is legally required and protects market integrity.
Eventual Consistency: The Middle Ground
Many AP systems use eventual consistency—a model where all nodes will eventually become consistent when network partitions heal, even though they might temporarily disagree.
Key concepts:
-
Conflict-free Replicated Data Types (CRDTs)
- Data structures designed to merge automatically without conflicts
- Used in collaborative tools, distributed databases
- Example: A counter that only increments (each node can increment independently, then values are summed)
-
Vector Clocks
- Mechanism to determine the ordering of events in distributed systems
- Helps identify concurrent updates and conflicts
- Used by Cassandra, Riak, and DynamoDB
-
Last-Write-Wins (LWW)
- Simple conflict resolution: use timestamp to pick the “winner”
- Easy to implement but can lose data
- Used when losing some updates is acceptable
-
Read Repair and Anti-Entropy
- Background processes that detect and fix inconsistencies
- Read repair: fix inconsistencies when detected during reads
- Anti-entropy: periodically compare and sync data between nodes
Real-world example: Amazon’s shopping cart uses eventual consistency with a “merge” strategy. If network issues cause you to add the same item from two different sessions, the cart merges both additions rather than choosing one.
Tunable Consistency: Having Your Cake and Eating It Too
Modern databases like Cassandra and DynamoDB offer tunable consistency—you can choose the consistency level per query.
Cassandra consistency levels:
- ONE: Only one replica must acknowledge (fastest, least consistent)
- QUORUM: Majority of replicas must acknowledge (balanced)
- ALL: All replicas must acknowledge (slowest, most consistent)
Example use case:
// Writing a user's last login time (eventual consistency is fine)
await cassandra.execute(query, params, { consistency: ONE });
// Reading account balance (need strong consistency)
const balance = await cassandra.execute(query, params, { consistency: ALL });
// Social media feed (balanced approach)
const feed = await cassandra.execute(query, params, { consistency: QUORUM });This flexibility lets you optimize per use case:
- Profile photos: Low consistency (ONE)
- Friend lists: Medium consistency (QUORUM)
- Financial data: High consistency (ALL)
Common Misconceptions About CAP
Misconception 1: “CAP is a binary choice”
Reality: Modern systems often have different consistency requirements for different data types. You can mix strategies within the same application.
Misconception 2: “You always need to choose during design”
Reality: The choice happens during network partitions. When the network is healthy, you can have all three properties. CAP only matters when things go wrong.
Misconception 3: “AP systems are always inconsistent”
Reality: AP systems use eventual consistency. They become consistent over time. The inconsistency window is usually milliseconds to seconds.
Misconception 4: “CP systems are always unavailable”
Reality: CP systems are available most of the time. They only sacrifice availability during partitions, which are rare events.
Misconception 5: “CAP means you can only have 2 properties ever”
Reality: You can have all three during normal operation. CAP describes behavior during network partitions specifically.
Making the Right Choice for Your System
Choose CP when:
- ✅ Correctness is more important than availability
- ✅ You’re dealing with financial transactions, inventory, or other critical data
- ✅ Users can tolerate occasional downtime
- ✅ Inconsistency could cause legal, financial, or safety issues
- ✅ Examples: Banking, ticketing, healthcare records, e-commerce checkout
Choose AP when:
- ✅ Availability is more important than immediate consistency
- ✅ You can tolerate temporary inconsistencies
- ✅ Downtime would drive users away
- ✅ You’re dealing with social content, caching, or user-generated data
- ✅ Examples: Social media, CDNs, analytics, recommendations, session storage
Questions to ask yourself:
-
What happens if a user sees stale data?
- If catastrophic: Choose CP
- If annoying but acceptable: Choose AP
-
What happens if the system is temporarily unavailable?
- If users will leave: Choose AP
- If users will wait: Choose CP
-
Can conflicts be resolved automatically?
- If yes: AP might work
- If no: Consider CP
-
What’s your consistency window tolerance?
- Milliseconds acceptable: AP with eventual consistency
- Zero tolerance: CP with strong consistency
Advanced Patterns and Solutions
Multi-Region Strategies
Strategy 1: Primary-Backup (CP)
- One region is primary, others are backups
- All writes go to primary
- Strong consistency but regional failover causes downtime
Strategy 2: Multi-Master (AP)
- All regions accept writes
- Conflicts resolved through CRDTs or conflict resolution strategies
- High availability but eventual consistency
Strategy 3: Sharding by Geography
- European users’ data in Europe, Asian users’ data in Asia
- Reduces need for cross-region coordination
- Best of both worlds for region-specific data
The PACELC Theorem: Beyond CAP
PACELC extends CAP by considering trade-offs even when the system is running normally:
PAC: During Partitions, choose between Availability and Consistency (same as CAP)
ELC: Else (normal operation), choose between Latency and Consistency
Examples:
- MongoDB: PC/EC (Consistency over both Availability and Latency)
- Cassandra: PA/EL (Availability and Latency over Consistency)
- DynamoDB: PA/EL by default, but tunable
Implementation Examples
Example 1: Building a Distributed Cache (AP)
class DistributedCache {
constructor(nodes) {
this.nodes = nodes; // Array of cache nodes
}
async set(key, value, ttl = 3600) {
// Hash key to determine primary node
const primaryNode = this.getNodeForKey(key);
// Write to primary node (don't wait for replication)
await primaryNode.set(key, value, ttl);
// Asynchronously replicate to other nodes (fire and forget)
this.replicateAsync(key, value, ttl, primaryNode);
return true; // Return immediately (availability)
}
async get(key) {
const node = this.getNodeForKey(key);
try {
// Try primary node first
return await node.get(key);
} catch (error) {
// If primary fails, try other nodes (availability)
return await this.getFallback(key);
}
}
async replicateAsync(key, value, ttl, excludeNode) {
// Don't wait for this - eventual consistency
this.nodes
.filter(node => node !== excludeNode)
.forEach(node => {
node.set(key, value, ttl).catch(err => {
// Log error but don't fail the operation
console.error("Replication failed:", err);
});
});
}
async getFallback(key) {
// Try all nodes until one responds
for (const node of this.nodes) {
try {
const value = await node.get(key);
if (value) return value;
} catch (error) {
continue; // Try next node
}
}
return null; // All nodes failed
}
getNodeForKey(key) {
// Consistent hashing to determine which node
const hash = this.hashCode(key);
const index = hash % this.nodes.length;
return this.nodes[index];
}
hashCode(str) {
let hash = 0;
for (let i = 0; i < str.length; i++) {
hash = (hash << 5) - hash + str.charCodeAt(i);
hash |= 0;
}
return Math.abs(hash);
}
}
// Usage
const cache = new DistributedCache([node1, node2, node3]);
// Set is fast and always succeeds (AP)
await cache.set("user:123", { name: "Alice" });
// Get might return stale data from fallback node during partitions
const user = await cache.get("user:123");Example 2: Building a Distributed Lock Service (CP)
class DistributedLock {
constructor(nodes) {
this.nodes = nodes;
this.quorum = Math.floor(nodes.length / 2) + 1;
}
async acquireLock(resource, ttl = 10000) {
const lockId = this.generateLockId();
const promises = this.nodes.map(node =>
this.tryAcquireOnNode(node, resource, lockId, ttl)
);
// Wait for all nodes to respond
const results = await Promise.allSettled(promises);
const successes = results.filter(
r => r.status === "fulfilled" && r.value
).length;
if (successes >= this.quorum) {
// Got quorum - lock acquired (consistency guaranteed)
return { acquired: true, lockId };
} else {
// Didn't get quorum - release partial locks and fail
await this.releaseLock(resource, lockId);
return { acquired: false }; // Sacrificing availability for consistency
}
}
async tryAcquireOnNode(node, resource, lockId, ttl) {
try {
// Atomic SET NX (set if not exists) with expiry
const result = await node.set(`lock:${resource}`, lockId, {
NX: true,
PX: ttl,
});
return result === "OK";
} catch (error) {
return false;
}
}
async releaseLock(resource, lockId) {
const script = `
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
`;
const promises = this.nodes.map(node =>
node.eval(script, [`lock:${resource}`], [lockId])
);
await Promise.allSettled(promises);
}
generateLockId() {
return `${Date.now()}-${Math.random()}`;
}
}
// Usage
const lockService = new DistributedLock([node1, node2, node3]);
// Acquire lock - blocks until quorum agrees (CP)
const lock = await lockService.acquireLock("payment:user123");
if (lock.acquired) {
try {
// Critical section - safe to process payment
await processPayment();
} finally {
// Always release lock
await lockService.releaseLock("payment:user123", lock.lockId);
}
} else {
// Lock acquisition failed - system prioritized consistency
throw new Error("Could not acquire lock - try again later");
}Example 3: Shopping Cart with Conflict Resolution (AP)
class ShoppingCart {
constructor(userId, db) {
this.userId = userId;
this.db = db; // Eventually consistent database
}
async addItem(productId, quantity) {
const timestamp = Date.now();
const operation = {
type: "ADD",
productId,
quantity,
timestamp,
nodeId: this.getNodeId(),
};
// Write locally immediately (availability)
await this.db.write(
`cart:${this.userId}:ops`,
operation,
{ consistency: "ONE" } // Prioritize speed
);
return { success: true };
}
async getCart() {
// Read from multiple replicas
const operations = await this.db.read(`cart:${this.userId}:ops`, {
consistency: "QUORUM",
});
// Merge operations using conflict resolution
return this.mergeOperations(operations);
}
mergeOperations(operations) {
const cart = {};
// Sort by timestamp to establish order
operations.sort((a, b) => a.timestamp - b.timestamp);
for (const op of operations) {
if (op.type === "ADD") {
cart[op.productId] = (cart[op.productId] || 0) + op.quantity;
} else if (op.type === "REMOVE") {
cart[op.productId] = Math.max(
0,
(cart[op.productId] || 0) - op.quantity
);
}
}
return cart;
}
getNodeId() {
// Identify which node handled this operation
return process.env.NODE_ID || "unknown";
}
}
// During network partition:
// User adds item from mobile app -> Writes to Node A
// User adds item from web browser -> Writes to Node B
// When partition heals, both operations are merged automaticallyMonitoring and Operating CAP Systems
Key Metrics to Monitor
For CP Systems:
- Write rejection rate during partitions
- Time to detect partitions
- Quorum achievement latency
- Split-brain scenarios
- Recovery time after partition heals
For AP Systems:
- Replication lag between nodes
- Conflict resolution frequency
- Data inconsistency windows
- Convergence time (how long until consistency)
- Stale read rates
Handling Partitions Gracefully
class PartitionDetector {
constructor(nodes, checkInterval = 5000) {
this.nodes = nodes;
this.checkInterval = checkInterval;
this.partitionState = new Map();
}
async startMonitoring() {
setInterval(() => this.checkPartitions(), this.checkInterval);
}
async checkPartitions() {
for (const nodeA of this.nodes) {
for (const nodeB of this.nodes) {
if (nodeA === nodeB) continue;
const canCommunicate = await this.pingNode(nodeA, nodeB);
const key = `${nodeA.id}-${nodeB.id}`;
if (!canCommunicate && !this.partitionState.has(key)) {
// New partition detected
this.partitionState.set(key, Date.now());
await this.handlePartitionDetected(nodeA, nodeB);
} else if (canCommunicate && this.partitionState.has(key)) {
// Partition healed
const duration = Date.now() - this.partitionState.get(key);
this.partitionState.delete(key);
await this.handlePartitionHealed(nodeA, nodeB, duration);
}
}
}
}
async handlePartitionDetected(nodeA, nodeB) {
console.error(`Partition detected between ${nodeA.id} and ${nodeB.id}`);
// For CP systems: might trigger read-only mode or reject writes
// For AP systems: might start tracking conflicts more carefully
// Alert operations team
await this.sendAlert({
type: "PARTITION_DETECTED",
nodes: [nodeA.id, nodeB.id],
timestamp: Date.now(),
});
}
async handlePartitionHealed(nodeA, nodeB, duration) {
console.log(`Partition healed after ${duration}ms`);
// Trigger reconciliation process
await this.reconcileNodes(nodeA, nodeB);
// Alert that system is back to normal
await this.sendAlert({
type: "PARTITION_HEALED",
nodes: [nodeA.id, nodeB.id],
duration,
});
}
async pingNode(nodeA, nodeB) {
try {
const response = await nodeA.ping(nodeB, { timeout: 1000 });
return response.success;
} catch (error) {
return false;
}
}
async reconcileNodes(nodeA, nodeB) {
// Sync data between nodes after partition heals
// Implementation depends on your consistency model
}
}AI Image Prompts for Your Article
Here are AI image generation prompts you can use to create visuals for this article:
1. Hero Image (CAP Triangle): “A modern, clean 3D illustration of a triangle with three glowing vertices labeled C, A, and P, floating in a dark blue tech background with subtle network connections, professional tech blog style, high quality render”
2. Consistency Concept: “A synchronized network of interconnected nodes all showing the same data simultaneously, glowing blue lines connecting them, isometric view, modern tech illustration, clean design”
3. Availability Concept: “Multiple server nodes in a network, some nodes glowing green (active) and some dimmed (offline), but connections still flowing around failed nodes, resilient system illustration, modern flat design”
4. Partition Tolerance: “A distributed network split in two halves with a broken connection in the middle, both sides still functioning independently, dark background with neon accents, technical diagram style”
5. CP System Example (Banking): “Abstract illustration of a bank vault with synchronized locks on multiple doors, all locks must align before opening, security and consistency theme, professional financial tech aesthetic”
6. AP System Example (Social Media): “Social media feed interface showing content flowing even during network issues, users staying connected with eventual sync icons, modern UI design, colorful and engaging”
7. Real-World Scenarios Comparison: “Split screen comparison: left side showing error message (CP system) during network issue, right side showing cached content loading (AP system), professional UX/UI design”
8. Eventual Consistency: “Ripple effect visualization of data propagating across distributed nodes over time, nodes gradually synchronizing, timeline animation concept, clean tech aesthetic”
Conclusion
The CAP theorem isn’t just theoretical computer science—it’s a practical framework that shapes how we build modern distributed systems. Every time you use Netflix, make a bank transfer, or scroll through social media, you’re experiencing CAP theorem decisions in action.
Key takeaways:
-
Partitions are inevitable in distributed systems, so you’re really choosing between consistency and availability when things go wrong
-
There’s no universally “best” choice—it depends on your specific use case and business requirements
-
Modern systems often use hybrid approaches, choosing different trade-offs for different data types or operations
-
Eventual consistency is powerful when implemented correctly with proper conflict resolution
-
The choice matters most during failures, not during normal operation
As you design your next distributed system, remember: understanding CAP isn’t about memorizing rules—it’s about making informed trade-offs that align with your users’ needs and your business requirements. Sometimes users need certainty (choose CP), and sometimes they need accessibility (choose AP). The art is knowing which matters more for each piece of your system.
The CAP theorem won’t tell you what to build, but it will help you understand the fundamental constraints and trade-offs you’ll navigate on your journey to building robust, scalable distributed systems.
Further Reading:
- Eric Brewer’s original CAP theorem paper (2000)
- “Designing Data-Intensive Applications” by Martin Kleppmann
- AWS Architecture Blog on DynamoDB consistency models
- Google’s Spanner paper on globally distributed databases
- Jepsen.io for real-world distributed systems testing and analysis